This repository shows how to distribute explanations with KernelSHAP one a single node or a Kubernetes cluster using ray. The predictions of a logistic regression model on 2560 instances from the Adult dataset are explained using KernelSHAP configured with a background set of 100 samples from the same dataset. The data preprocessing and model fitting steps are available in the scripts/ folder, but both the data and the model will be automatically downloaded by the benchmarking scripts.
- Install
conda - Create a virtual environment with
conda create --name shap python=3.7 - Activate the environment with
conda activate shap - Execute
pip install .in order to install the dependencies needed to run the benchmarking scripts
Two code versions are available:
- One using a parallel pool of
rayactors, which consume small subsets of the2560dataset to be explained - One using
ray serveinstead of the parallel pool
The two methods can be run from the repository root, using the scripts benchmarks/ray_pool.py and bechmarks/serve_explanations.py, respectively. Options that can be configured are:
- number of actors/replicas that the task is going to be distributed on (e.g.,
--workers 5(pool),--replicas 5(ray serve)) - if a benchmark (i.e., redistributing the task over an increasingly large pool or number of replicas) is to be performed (
-benchmark 0to disable orbenchmark 1to enable) - the number of times the task is run for the same configuration in benchmarking mode (e.g,
--nruns 5) - how many instances can be sent to an actor/replica at once (this is a required argument) (e.g.,
-b 1 5 10(pool)-batch 1 5 10(ray serve)). If more than one value is passed after the argument name, the task (or benchmarking) will be executed for different batch sizes
This requires you to have access to a Kubernetes cluster and have kubectl installed. Don't forget to export the path to the cluster configuration .yaml file in your KUBECONFIG environment variable, as described here before moving on to the next steps.
The ray_pool.py and serve_explanations.py have been modified to be deployable in the kubernetes and prefixed by k8s_. The benchmark experiments can be run via the bash scripts in the benchmarks/ folder. These scripts:
- Apply the appropriate k8s manifest in
cluster/to the k8s cluster - Upload a
k8s*.pyfile to it - Run the script
- Pull the results and save them in the
resultsdirectory
Specifically:
- Calling
bash benchmarks/k8s_benchmark_pool.sh 10 20will run the benchmark with increasing number of workers (the cluster is reset as the number of workers is increased). By default the experiment is run with batches of sizes1 5and10. This can be changed by updating the value ofBATCHincluster/Makefile.pool - Calling
bash benchmarks/k8s_benchmark_serve.sh 10 20 raywill run the benchmark with increasing number of workers and batch size of1 5and10for each worker. The batch size setting can be modified from the.shscript itself. Therayargument means thatrayis able to batch single requests together and dispatch them to the same worker. If replaced bydefault, minibatches will be distributed to each worker
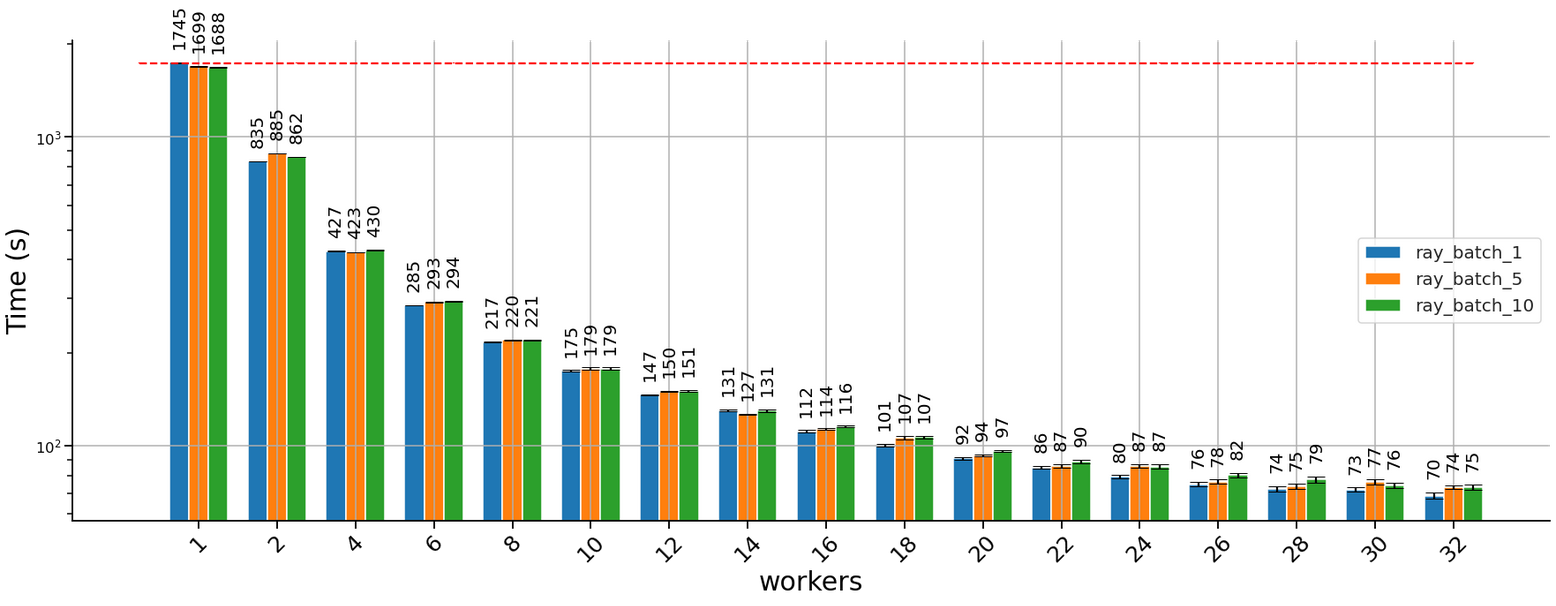
The experiments were run on a compute-optimized dedicated machine in Digital Ocean with 32vCPUs. This explains why the performance gains attenuation below.
The results obtained running the task using the ray parallel pool are below:

Distributing using ray serve yields similar results:

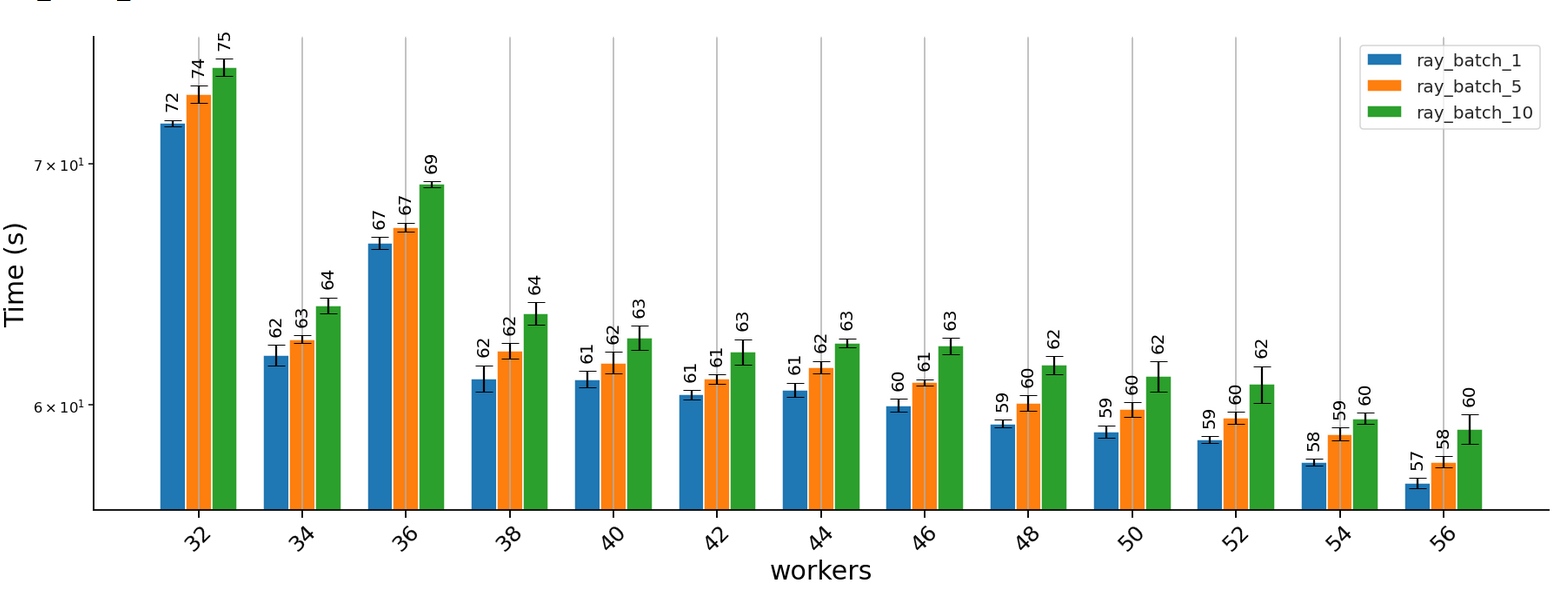
The experiments were run on a cluster consisting of two compute-optimized dedicated machine in Digital Ocean with 32vCPUs each. This explains why the performance gains attenuation below.
The results obtained running the task using the ray parallel pool over a two-node cluster are shown below:

Distributing using ray serve yields similar results: