



Senior AI / ML Research Engineer
Specializing in LLMs / VLMs / VLAs, Reinforcement Learning, and Embodied / Physical AI
I’m a senior AI/ML research engineer with 15+ years of experience building intelligent agents and AI systems that understand and reason about the world. My work spans foundation models, reinforcement learning, and physics-based simulation, continuously expanding into VLMs, VLAs, and embodied multimodal AI.
Currently part of the core research and engineering team at LawZero, a non-profit AI lab in Montreal led by Yoshua Bengio, I focus on advancing truthful, transparent, and safe-by-design AI through next-generation foundational models, and reasoning architectures.
My passion is right at the intersection of AI, simulation, and decision-making. I focus on:
- 🧠 Foundation Models & Alignment: LLM / VLM / VLA fine-tuning and alignment (SFT, DPO, RLHF/RLAIF) with a focus on interpretable, safe, and truthful reasoning.
- 🧭 Reinforcement Learning: Online/offline, adversarial, multi-agent, imitation learning, and human-in-the-loop optimization.
- 🛰️ Embodied AI & High-Fidelity Simulation: Isaac Lab, Genesis, and physics-based virtual environments for grounded RL and world modeling.
I’m always happy to chat with people who share my interests and passions. Feel free to reach out!
- 🌐 Personal Website
- 🧠 Artificial Twin - The brand behind my AI/ML consultancy activity with the mission of building intelligent agents
Here are a few of my public repositories that reflect my work and interests:
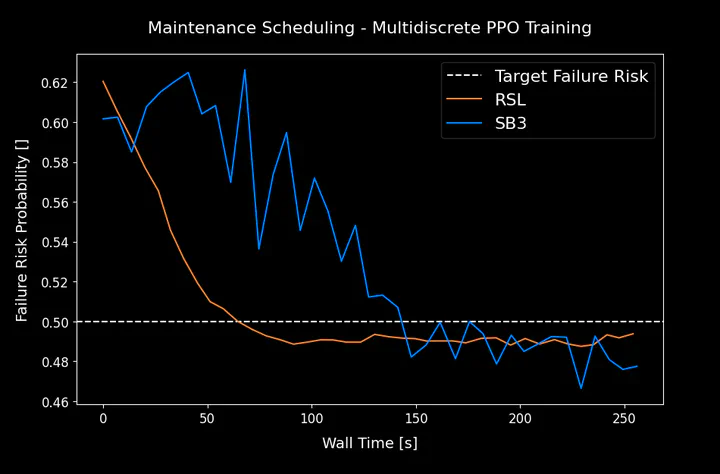
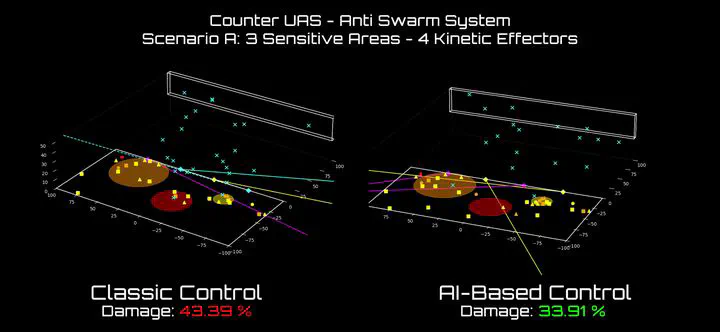
| 🔀 Extending GPU-Native RSL-RL Library | 🛡️ RL Drone Swarm Defense | 🕹️ DIAMBRA Arena | 🤖 DIAMBRA Agents |
|---|---|---|---|
|
|

|

|
| Customized fork of RSL-RL library that supports multi-discrete action spaces. | Counter-kamikaze drone swarm with multi-agent reinforcement learning in a realistic simulation. | A platform to train reinforcement learning agents in classic retro fighting games. | A library of reinforcement learning algorithms tailored for DIAMBRA Arena environments. |
- Experimenting with adversarial RL for LLM alignment fine-tuning
- Exploring speculative decoding for fast LLM inference
- Learning Triton to optimize GPU workloads for small-scale LLMs
- Testing agentic frameworks for multi-step coordination
- Moving toward Vision-Language-Action models