This project aims to benchmark various methods of copying data between TCP sockets, measuring both performance and CPU usage. The goal is to identify the fastest methods with the least amount of CPU overhead.
The benchmark tests the following methods:
- IoPipe: Utilizes the
io.Pipefunction for data transfer. - IoCopy: Uses the
io.Copyfunction. - IoCopyBuffer: Uses
io.CopyBufferfor buffered copying. - Syscall: Direct system calls for data transfer.
- IoCopyDirect: Direct copy using
io.Copy. - UnixSyscall: Unix-specific system calls.
- Bufio: Buffered I/O using
bufiopackage. - Splice: Linux
splicesystem call. - Sendfile: Uses the
sendfilesystem call. - ReadvWritev: Vectorized I/O operations using
readvandwritev.
We are using the net package to create a TCP server and client for data transfer. The server listens on a specified port, and the client connects to the server to send and receive data.
the payload size is set to 10Kb, and the number of iterations is set to 5000.
const (
address = "localhost:12345"
numClients = 5000
bufferSize = 32 * 1024
)
var (
message = generateRandomString(10240) // Generate a 10kb random string
messageLength = len(message)
)Tested on a base Hetzner instance with the following specifications:
- CPU: Intel Xeon (Skylake, IBRS, no TSX) (4) @ 2.099GHz
- RAM: 7747MiB
- OS: Ubuntu 22.04.4 LTS x86_64
The benchmark results are summarized as follows:
-
Execution Times (ns/op):
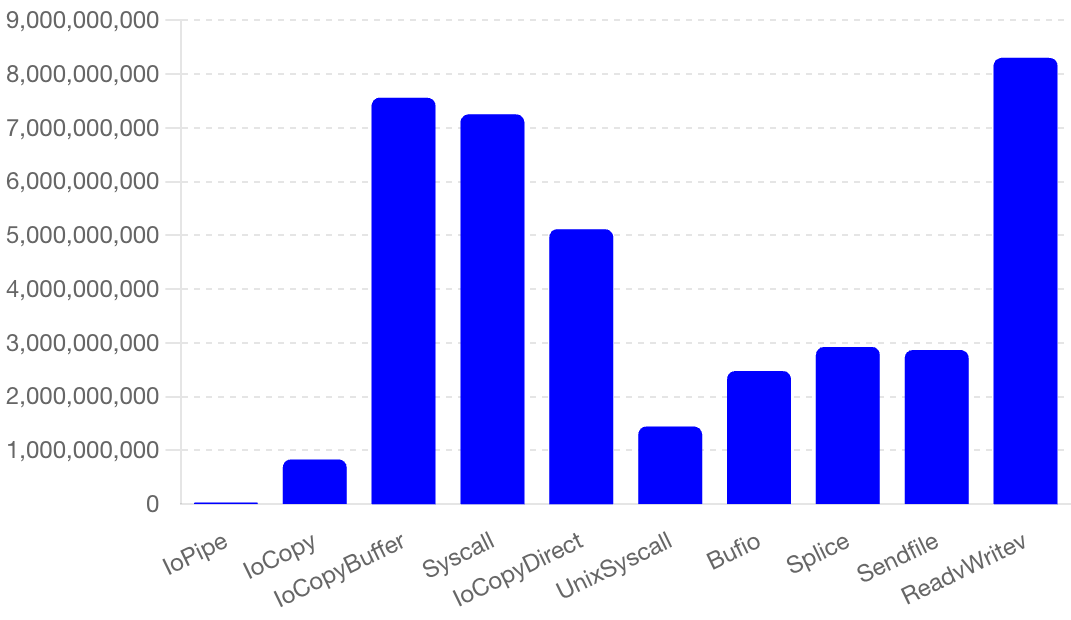
-
CPU Time (ms):
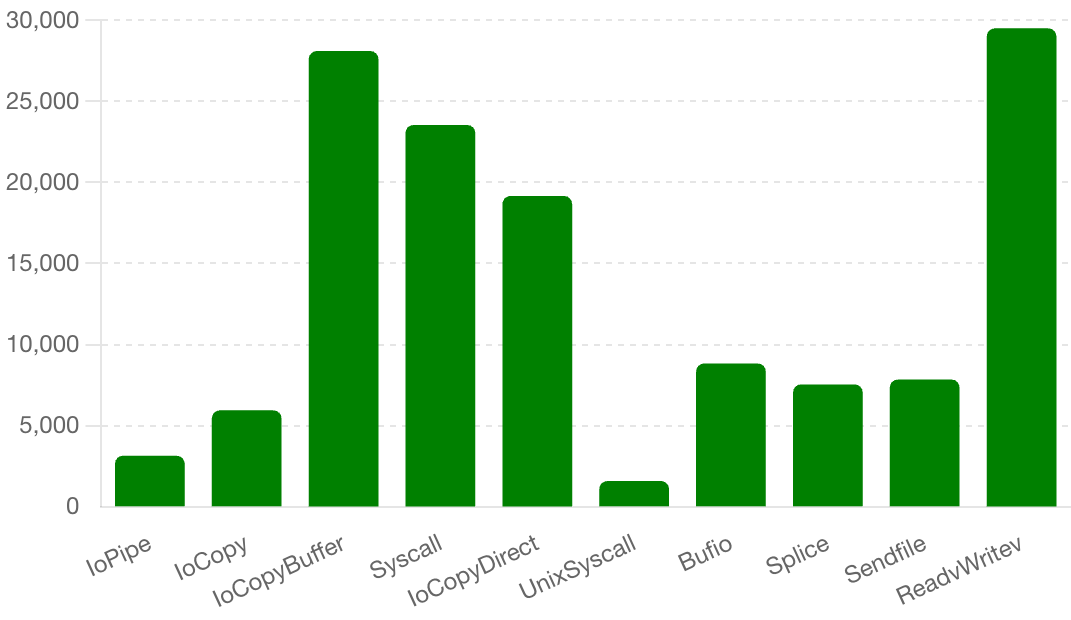
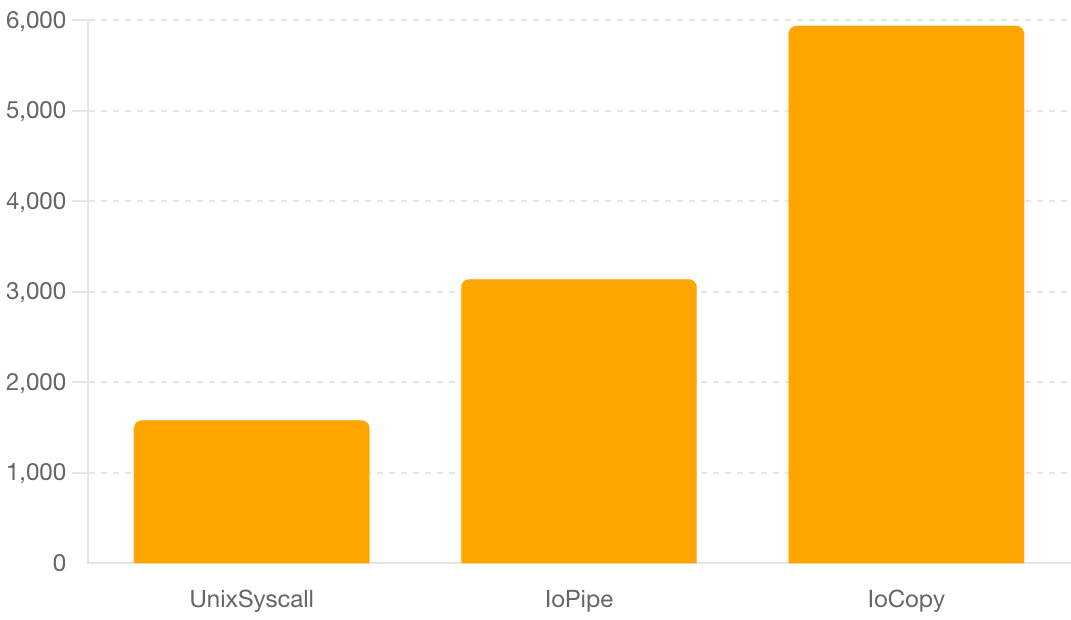
- UnixSyscall: 1580 ms
- IoPipe: 3140 ms
- IoCopy: 5940 ms
The IoPipe method stands out as a native solution working with the net.Conn interface, providing a balance between performance and CPU usage. However, methods such as UnixSyscall show the potential for further optimization by directly interfacing with the underlying system calls.
To execute the benchmarks and analyze the results, use the following commands:
go test -bench=. test/tcp_test.go && go run analyse.goThe above commands will run the benchmark tests and generate a detailed analysis of each method's performance.
The native UnixSyscall method provides the best performance with the least CPU overhead. However, the IoPipe method is a close second and offers a more straightforward implementation. The choice of method depends on the specific requirements of the application, balancing performance and resource utilization.